Introduction¶
Ce notebook implémente l’algorithme CQR (Conformalized Quantile Regression) afin de prédire des intervalles de prédiction pour le prix de voitures à partir de leurs caractéristiques.
Dans le cadre de la CQR, deux régresseurs quantiles sont utilisés pour effectuer les prédictions initiales. Contrairement à la méthode CV+, la calibration ne se fait pas par validation croisée, mais en utilisant les scores de conformité calculés sur un ensemble de calibration dédié (distinct de l’entraînement).
Sous des hypothèses d’échangeabilité des données, l’algorithme CQR produit des intervalles de prédiction avec des garanties théoriques sur la couverture. Les intervalles obtenus sont adaptatifs : ils s’appuient sur des régresseurs quantiles qui capturent localement la variabilité des données (hétéroscédasticité), puis sont “corrigés” globalement pour garantir le taux d’erreur cible.
Mise en place¶
Séparation des données : Les données sont séparées en trois ensembles : entraînement (proper training set), calibration et test.
Entraînement du modèle : Deux régresseurs quantiles sont entraînés sur l’ensemble d’entraînement (pour estimer les bornes brutes).
Calibration :
Les régresseurs quantiles effectuent des prédictions sur l’ensemble de calibration.
On calcule les scores de conformité sur cet ensemble. Ces scores mesurent l’écart (ou l’erreur signée) entre les bornes prédites et les vraies valeurs.
On détermine une constante de correction correspondant au quantile approprié de ces scores.
Construction des intervalles :
Les modèles prédisent les bornes initiales sur l’ensemble de test.
Ces bornes sont ajustées (élargies ou décalées) en leur appliquant la constante de correction issue de l’étape de calibration.
Évaluation du modèle: Le modèle est évalué sur l’ensemble de test en utilisant diverses métriques.
Chargement des données¶
import numpy as np
import polars as pl
# Polars display options
pl.Config.set_tbl_hide_column_data_types(True)
pl.Config.set_tbl_hide_dataframe_shape(True)
pl.Config.set_float_precision(2)
# Load preprocessed data
df = pl.read_parquet("../../data/car_prices_clean.parquet")
print(f"Dataset shape: {df.shape}")
df.head()Dataset shape: (19161, 18)
Définition des données du modèle¶
target = "Price"
numerical_features = [
"Production year",
"Leather interior",
"Engine volume (L)",
"Mileage (km)",
"Cylinders",
"Doors",
"Airbags",
"Turbo",
]
categorical_features = [
"Brand",
"Category",
"Fuel type",
"Gear box type",
"Drive wheels",
"Wheel",
"Color",
]
features = numerical_features + categorical_features
used_cols = set(features) | {target}
f"Columns not used: {set(df.columns) - used_cols}""Columns not used: ['Levy tax', 'Model']"Séparation des données¶
La taille de l’ensemble de calibration est choisie de manière à garantir un taux de couverture satisfaisant, tandis que la taille de l’ensemble de test permet de généraliser les performances du modèle.
from sklearn.model_selection import train_test_split
X = df.select(features)
y = df.get_column("Price")
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.4, random_state=42
)
X_calib, X_test, y_calib, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=42
)
print(f"Train set size (60%): {X_train.shape[0]}")
print(f"Calibration set size (20%): {X_calib.shape[0]}")
print(f"Test set size (20%): {X_test.shape[0]}")Train set size (60%): 11496
Calibration set size (20%): 3832
Test set size (20%): 3833
Définition du modèle¶
Le régresseur utilisé est sklearn.ensemble.HistGradientBoostingRegressor qui est un modèle de gradient boosting efficace pour les tâches de régression. Ce modèle est choisi car il ne nécessite pas de normalisation des données numériques et gère nativement les données catégorielles et manquantes.
Le paramètre loss est défini sur "quantile" pour entraîner un régresseur quantile. Deux modèles sont entraînés : un pour le quantile inférieur () et un pour le quantile supérieur (1 - ).
from sklearn.base import clone
from sklearn.ensemble import HistGradientBoostingRegressor
base_model = HistGradientBoostingRegressor(
loss="quantile",
quantile=None,
categorical_features="from_dtype",
early_stopping=True,
validation_fraction=0.1,
random_state=42,
)
alpha = 0.1 # 90% prediction intervals
q_low, q_high = alpha / 2, 1 - alpha / 2
print(f"Quantiles: {q_low}, {q_high}")
model_low = clone(base_model).set_params(quantile=q_low)
model_high = clone(base_model).set_params(quantile=q_high)Quantiles: 0.05, 0.95
Entraînement du modèle¶
Les hyperparamètres du modèle sont optimisés sur l’ensemble d’entraînement avec sklearn.model_selection.HalvingRandomSearchCV avec une cross-validation à 5 plis sur l’ensemble d’entraînement. Les meilleurs hyperparamètres sont ensuite utilisés pour entraîner le modèle final sur l’ensemble d’entraînement complet (refit=True).
from scipy.stats import randint, uniform
from sklearn.experimental import enable_halving_search_cv # noqa:F401
from sklearn.model_selection import HalvingRandomSearchCV
param_distributions = {
"max_iter": randint(100, 300),
"max_leaf_nodes": randint(20, 80),
"learning_rate": uniform(0.05, 0.15),
"min_samples_leaf": randint(20, 100),
"l2_regularization": uniform(0, 0.1),
}
base_search = HalvingRandomSearchCV(
estimator=None,
param_distributions=param_distributions,
n_candidates=50,
min_resources=200,
cv=5,
n_jobs=-1,
random_state=42,
refit=True,
)
search_low = clone(base_search).set_params(estimator=model_low)
search_high = clone(base_search).set_params(estimator=model_high)
search_low.fit(X_train, y_train)
search_high.fit(X_train, y_train);Predictions sur l’ensemble de test¶
df_test_QR = pl.DataFrame(
{
"True Price": y_test,
"Lower Bound": search_low.best_estimator_.predict(X_test),
"Upper Bound": search_high.best_estimator_.predict(X_test),
}
).with_columns(
(pl.col("Upper Bound") - pl.col("Lower Bound")).alias("Interval Width"),
)Distribution de la largeur d’intervalle¶
import matplotlib.pyplot as plt
plt.figure(figsize=(9, 3))
plt.hist(df_test_QR["Interval Width"], bins=50, log=True)
plt.axvline(
df_test_QR["Interval Width"].median(),
color="red",
linestyle="--",
linewidth=2,
label=f"Median Width = {df_test_QR['Interval Width'].median():.0f}",
)
plt.axvline(
df_test_QR["Interval Width"].mean(),
color="red",
linewidth=2,
label=f"Mean Width = {df_test_QR['Interval Width'].mean():.0f}",
)
plt.title("Distribution of Interval Widths")
plt.ylabel("Count (Log)")
plt.legend()
plt.tight_layout()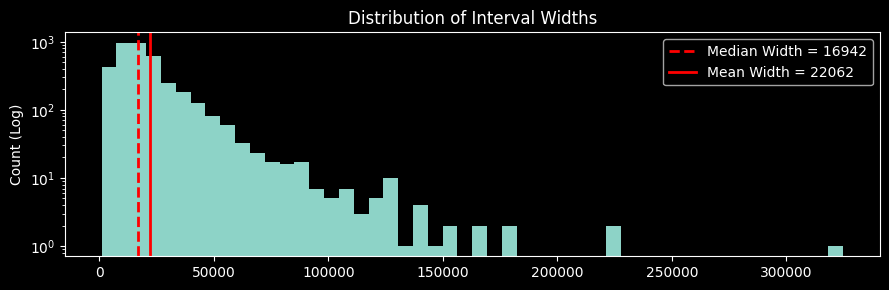
Évaluation de la régression quantile non conformalisée (QR)¶
from utils import coverage, pinball_loss
df_test_QR.select(
coverage("Lower Bound", "Upper Bound"),
coverage(0, "Lower Bound").name.suffix(f" q{q_low}"),
coverage(0, "Upper Bound").name.suffix(f" q{q_high}"),
pinball_loss("True Price", "Lower Bound", q_low),
pinball_loss("True Price", "Upper Bound", q_high),
pl.col("Interval Width").mean().round(),
)Le taux de couverture global (82.6%) est nettement inférieur au taux attendu (90%).
Toutefois, malgré cette sous-couverture globale, le regresseur quantile est meilleur que l’approche SCP. La pinball loss est nettement plus faible pour les deux bornes et la largeur moyenne des intervalles est également plus faible.
La conformalisation devrait améliorer le taux de couverture.
Conformalized quantile regression (CQR)¶
# 1. Predict quantiles on calibration set
cal_low_pred = search_low.best_estimator_.predict(X_calib)
cal_high_pred = search_high.best_estimator_.predict(X_calib)
# 2. Compute nonconformity scores
nonconformity_scores = np.maximum(cal_low_pred - y_calib, y_calib - cal_high_pred)
# 3. Compute quantile of nonconformity scores
q_level = np.ceil((len(y_calib) + 1) * (1 - alpha)) / len(y_calib)
qhat = np.quantile(nonconformity_scores, q_level, method="linear")
f"CQR calibration qhat (α={alpha}): {qhat:.3f} at level {q_level:.4f}"'CQR calibration qhat (α=0.1): 787.838 at level 0.9003'Distribution des scores de calibration¶
import matplotlib.pyplot as plt
plt.figure(figsize=(9, 3))
plt.hist(nonconformity_scores, bins=50, log=True)
plt.axvline(qhat, color="red", linestyle="--", linewidth=2, label=f"q={qhat:.2f}")
plt.title("Distribution Calibration Scores (Log Scale)")
plt.xlabel("score r = max(q_low - y, y - q_high)")
plt.ylabel("Count (Log)")
plt.legend()
plt.tight_layout()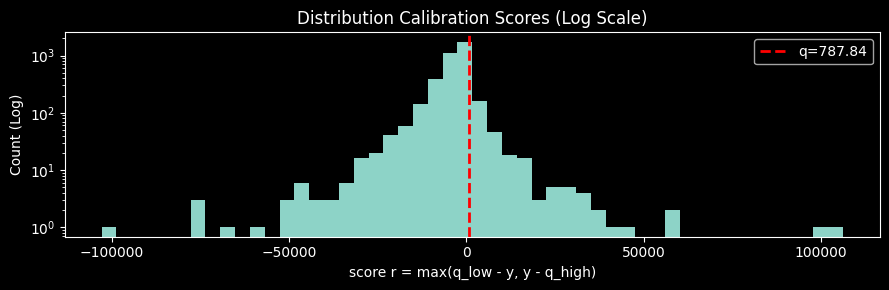
Prédictions des quantiles conformalisés (CQR) sur l’ensemble de test¶
df_test_CQR = df_test_QR.with_columns(
(pl.col("Lower Bound") - qhat).name.suffix(" CQR"),
(pl.col("Upper Bound") + qhat).name.suffix(" CQR"),
).with_columns(
(pl.col("Upper Bound CQR") - pl.col("Lower Bound CQR")).alias("Interval Width CQR")
)
# Largeur relative des intervalles par rapport au prix
df_test_CQR = df_test_CQR.with_columns(
pl.col("Interval Width CQR")
.truediv("True Price")
.mul(100)
.round(2)
.alias("CQR Interval Width Relative to True Price"),
)
df_test_CQR = pl.concat([df_test_CQR, X_test], how="horizontal")
df_test_CQR.head()Évaluation des performances (CQR)¶
df_test_CQR.select(
coverage("Lower Bound CQR", "Upper Bound CQR").alias("Coverage CQR"),
coverage(0, "Lower Bound CQR").name.suffix(f" CQR q{q_low}"),
coverage(0, "Upper Bound CQR").name.suffix(f" CQR q{q_high}"),
pinball_loss("True Price", "Lower Bound CQR", q_low),
pinball_loss("True Price", "Upper Bound CQR", q_high),
pl.col("Interval Width CQR").mean().cast(pl.Int32),
)Les bornes calibrées corrigent le biais résiduel des régressions quantiles: le duo (q_low, q_high) sous-couvre légèrement, l’agrégat q̂ appris sur l’échantillon de calibration élargit symétriquement l’intervalle pour corriger la sous-couverture et atteindre la couverture cible, sans hypothèses fortes sur la distribution des erreurs. La pinball loss reste similaire à celle des régressions quantiles non conformalisées.
Couverture par décile de prix (QR vs CQR)¶
df_test_CQR.with_columns(
pl.col("True Price").qcut(10, include_breaks=True).alias("True Price Decile")
).group_by("True Price Decile").agg(
coverage("Lower Bound", "Upper Bound").alias("Coverage QR"),
coverage("Lower Bound CQR", "Upper Bound CQR").alias("Coverage CQR"),
pl.col("Interval Width").mean().cast(pl.Int32),
pl.col("Interval Width CQR").mean().cast(pl.Int32),
pl.col("Lower Bound CQR").mean().round(0).alias("Avg Lower Bound CQR"),
pl.col("Upper Bound CQR").mean().round(0).alias("Avg Upper Bound CQR"),
).sort("True Price Decile")Le taux de couverture des intervalles produit par la régression quantile par décile de prix montre que le modèle sous-couvre sur l’ensemble des déciles, avec des performances particulièrement mauvaise sur les véhicules les moins chers (1er décile) et les plus chers (10ème décile).
Le taux de couverture par décile de prix montre que le modèle a plus de difficultés à couvrir correctement les véhicules aux extrémités de la gamme de prix et en particulier le 10ème décile (les véhicules les plus chers), où la couverture tombe à 74,3%.
La conformalisation a permis de corriger partiellement mais uniformément ce problème aux différents déciles de prix.
Largeurs d’intervalles moyenne vs kilométrage¶
import altair as alt
alt.data_transformers.enable("vegafusion")
_df_temp = df_test_CQR.filter(
pl.col("Mileage (km)").is_between(0, 500_000)
& pl.col("Interval Width CQR").is_between(0, 150_000)
)
alt.Chart(_df_temp).mark_rect().encode(
alt.X("Interval Width CQR:Q").bin(maxbins=50),
alt.Y("Mileage (km):Q").bin(maxbins=50),
alt.Color("count()").scale(type="sqrt"),
).properties(title="CQR Interval Width vs Mileage (Density Plot)")Main Concentration: The highest density of records (darkest blue) is clustered at low-to-mid mileage (approx. 80,000 to 200,000 km) and a low absolute interval width (approx. 10,000 to 30,000). This suggests the model is most frequently making predictions for cars in this range and is generating relatively tight absolute intervals for them.
Low Mileage Behavior: For very low mileage vehicles (0 to 80,000 km), the distribution is much more spread out vertically. This indicates a high variance in prediction uncertainty; some predictions have very narrow intervals, while others have extremely wide intervals (up to 150,000).
High Mileage Behavior: For vehicles with high mileage (over 320,000 km), there are very few data points, and the interval widths are generally low to moderate.
Largeurs d’intervalles relatifs aux vrai prix moyen vs kilométrage¶
_df_temp = df_test_CQR.filter(
pl.col("Mileage (km)").is_between(0, 500_000)
& pl.col("CQR Interval Width Relative to True Price").is_between(0, 300)
)
alt.Chart(_df_temp).mark_rect().encode(
alt.X("CQR Interval Width Relative to True Price:Q").bin(maxbins=50),
alt.Y("Mileage (km):Q").bin(maxbins=50),
alt.Color("count()").scale(type="sqrt"),
).properties(
title="CQR Interval Width Relative to True Price (%) vs Mileage (Density Plot)"
)La plupart des intervalles de prédiction sont relativement étroits (entre 50% et 120% du prix réel). Cependant, pour les véhicules avec un faible kilométrage, on observe une plus grande variabilité dans la largeur des intervalles, ce qui suggère une incertitude accrue dans les prédictions pour ces véhicules.
_df_temp = df_test_CQR.filter(
pl.col("CQR Interval Width Relative to True Price").is_between(0, 600)
& pl.col("True Price").is_between(0, 200_000)
)
alt.Chart(_df_temp).mark_rect().encode(
alt.X("CQR Interval Width Relative to True Price:Q").bin(maxbins=50),
alt.Y("True Price:Q").bin(maxbins=50),
alt.Color("count()").scale(type="sqrt"),
).properties(
title="CQR Relative Interval Width to True Price vs True Price (Density Plot)"
)On observe clairement une relation inverse entre le prix réel et la largeur relative des intervalles de prédiction: les véhicules moins chers ont des intervalles proportionnellement plus larges, tandis que les véhicules plus chers bénéficient d’intervalles plus étroits en pourcentage de leur prix.
_df_temp = df_test_CQR.filter(
pl.col("Production year").is_between(1990, 2020)
& pl.col("Interval Width CQR").is_between(0, 150_000)
)
alt.Chart(_df_temp).mark_rect(clip=True).encode(
alt.X("Production year:Q").bin(maxbins=50),
alt.Y("Interval Width CQR:Q").bin(maxbins=50),
alt.Color("count()").scale(type="sqrt"),
).properties(title="CQR Interval Width vs Production year (Density Plot)")Analyse de la couverture par sous-groupes¶
df_test_CQR.group_by("Brand").agg(
coverage("Lower Bound CQR", "Upper Bound CQR"), pl.len().alias("Count")
).sort("Count", descending=True).head(10)df_test_CQR.group_by("Fuel type").agg(
coverage("Lower Bound CQR", "Upper Bound CQR"), pl.len().alias("Count")
).sort("Count", descending=True)df_test_CQR.group_by("Production year").agg(
coverage("Lower Bound CQR", "Upper Bound CQR"), pl.len().alias("Count")
).sort("Production year", descending=True).head(15)Analyse par sous-groupes:
La couverture peut varier légèrement selon les caractéristiques du véhicule (kilométrage, année, marque) toutefois ces variations restent plus limitées qu’avec l’algorithme SCP.