Introduction¶
Ce notebook implémente la méthode SCP (Split Conformal Prediction) adaptée aux problèmes de classification.Contrairement à la régression où l’on cherche à prédire un intervalle continu , l’objectif ici est de construire un ensemble de prédiction (une liste de classes) susceptible de contenir la vraie classe.
Le défi de l’incertitude en classification¶
Dans une classification multi-classe standard, le modèle renvoie souvent la classe ayant la probabilité la plus élevée. Cependant, si un modèle prédit “Sapin” avec 35% de probabilité et “Pin” avec 34%, choisir uniquement “Sapin” est risqué.
La méthode SCP permet de transformer ces probabilités brutes en un ensemble de classes garantissant que la vraie classe s’y trouve avec une probabilité .
Méthode “Threshold” (Naive SCP)¶
L’approche implémentée ici est la version “Threshold” :
On calcule les probabilités pour chaque classe.
On définit un score de non-conformité basé sur la probabilité de la vraie classe : .
Sur l’ensemble de calibration, on trouve le seuil critique tel que 99% des vraies classes ont une probabilité .
Pour une nouvelle prédiction, on inclut dans l’ensemble final toutes les classes dont la probabilité dépasse ce seuil.
Chargement des données¶
import numpy as np
import polars as pl
# Polars display options
pl.Config.set_tbl_hide_column_data_types(True)
pl.Config.set_tbl_hide_dataframe_shape(True)
pl.Config.set_float_precision(2)
# Load preprocessed data
df = pl.read_parquet("../../data/forest_cover_clean.parquet")
print(f"Dataset shape: {df.shape}")
df.head()Dataset shape: (581012, 13)
Séparation des données¶
from sklearn.model_selection import train_test_split
y = df.drop_in_place("Cover_Type")
X = df
# 60% train, 20% calibration, 20% test split
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.4, random_state=42
)
X_calib, X_test, y_calib, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=42
)
print(f"Train set size (60%): {X_train.shape[0]}")
print(f"Calibration set size (20%): {X_calib.shape[0]}")
print(f"Test set size (20%): {X_test.shape[0]}")Train set size (60%): 348607
Calibration set size (20%): 116202
Test set size (20%): 116203
Définition du modèle¶
Au regard de la taille du dataset et du temps d’entraînement ( minute), nous n’allons pas optimiser les hyperparamètres.
from sklearn.ensemble import HistGradientBoostingClassifier
model = HistGradientBoostingClassifier(
loss="log_loss",
learning_rate=0.1,
max_iter=2000,
max_depth=None,
max_leaf_nodes=127,
min_samples_leaf=50,
l2_regularization=0.5,
categorical_features="from_dtype",
early_stopping=True,
n_iter_no_change=20,
validation_fraction=0.1,
class_weight="balanced", # Covertype classes are heavily imbalanced
random_state=42,
)
model.fit(X_train, y_train);Évaluation du modèle de base¶
from sklearn.metrics import classification_report
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred)) precision recall f1-score support
1 0.94 0.94 0.94 42218
2 0.96 0.94 0.95 56895
3 0.95 0.96 0.96 7075
4 0.88 0.89 0.88 536
5 0.81 0.94 0.87 1933
6 0.89 0.96 0.92 3449
7 0.95 0.98 0.96 4097
accuracy 0.94 116203
macro avg 0.91 0.94 0.93 116203
weighted avg 0.94 0.94 0.94 116203
Le modèle de base est excellent.
Implémentation de l’algorithme SCP¶
Dans le cadre de la classification, la méthode SCP utilise les probabilités prédites par le modèle pour construire un score de non-conformité défini par , où est la probabilité estimée de la vraie classe.
L’ensemble de prédiction pour une nouvelle observation est construit en incluant toutes les classes telles que , où est le quantile des scores de non-conformité calculés sur l’ensemble de calibration.
# 1. Predict probabilities on calibration set
y_calib_pred_proba = model.predict_proba(X_calib)
classes = model.classes_
# 2. Compute nonconformity scores (1 - softmax probability of true class)
y_calib_np = y_calib.to_numpy()
# Get the index of the true class for each sample
# We assume classes are mapped to indices 0..K-1 in the proba array
# model.classes_ gives the mapping
class_to_idx = {c: i for i, c in enumerate(classes)}
class_indices = np.array([class_to_idx[y] for y in y_calib_np])
# Extract probabilities of true classes
# y_calib_pred_proba is shape (n_samples, n_classes)
prob_true_class = y_calib_pred_proba[np.arange(len(y_calib)), class_indices]
# Score = 1 - prob_true_class
nonconformity_scores = 1 - prob_true_class# 3. Compute quantile
alpha = 0.01
n = len(nonconformity_scores)
q_level = np.ceil((n + 1) * (1 - alpha)) / n
qhat = np.quantile(nonconformity_scores, q_level, method="linear")
print(f"SCP calibration qhat (α={alpha}): {qhat:.4f}")SCP calibration qhat (α=0.01): 0.8516
Distribution des scores de non-conformité¶
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.hist(
nonconformity_scores,
bins=50,
alpha=0.7,
edgecolor="k",
label="Nonconformity scores",
)
plt.axvline(
qhat, color="red", linestyle="--", label=f"Quantile ({1 - alpha:.2f}) = {qhat:.4f}"
)
plt.xlabel("Nonconformity Score (1 - P(True Class))")
plt.ylabel("Frequency")
plt.title("Distribution of Nonconformity Scores on Calibration Set")
plt.legend()
plt.show()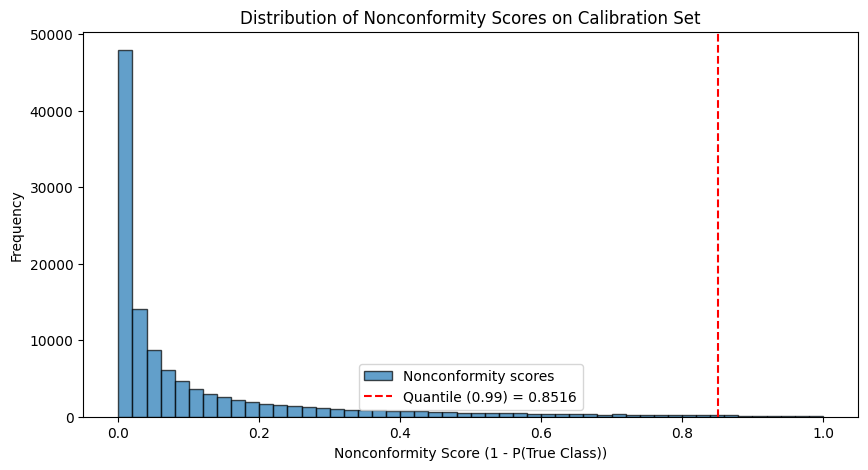
Les ensembles de prédiction sont construits pour l’ensemble de test.
# 4. Predict on test set
y_test_pred_proba = model.predict_proba(X_test)
# 5. Build prediction sets
# Include class k if 1 - P(y=k|x) <= qhat
prediction_sets = []
for probs in y_test_pred_proba:
# classes where probability is high enough
pset = classes[probs >= (1 - qhat)]
prediction_sets.append(pset)
# Create results DataFrame
df_test_results = pl.DataFrame(
{
"True Class": y_test,
"Prediction Set": prediction_sets,
}
).with_columns(pl.col("Prediction Set").list.len().alias("Cardinality"))
# Add features for analysis
df_test_full = pl.concat([df_test_results, X_test], how="horizontal")
df_test_full.head()Évaluation des performances¶
df_test_full.describe()Définition des métriques de performances¶
coverage = (
pl.col("Prediction Set")
.list.contains(pl.col("True Class"))
.mean()
.mul(100)
.round(2)
.alias("Coverage")
)
avg_set_size = pl.col("Cardinality").mean().round(2).alias("Average Cardinality")
singleton_rate = (pl.col("Cardinality") == 1).mean().round(2).alias("Singleton Rate")
print(f"Coverage: {df_test_full.select(coverage).item()}% (target: 99%)")
print(f"Average Cardinality: {df_test_full.select(avg_set_size).item()} elements")
print(f"Singleton Rate: {df_test_full.select(singleton_rate).item()}%")Coverage: 99.01% (target: 99%)
Average Cardinality: 1.22 elements
Singleton Rate: 0.78%
Analyse de la couverture par classe¶
df_test_full.group_by("True Class").agg(
coverage,
avg_set_size,
singleton_rate,
pl.len().alias("Count"),
).sort("True Class")Analyse de la couverture par taille d’ensemble¶
df_test_full.group_by("Cardinality").agg(
coverage,
pl.len().alias("Count"),
).sort("Cardinality")