Dans ce notebook, nous appliquons SHAP (SHapley Additive exPlanations) pour expliquer les prédictions d’un modèle XGBoost entraîné sur le jeu de données Breast Cancer Wisconsin (Diagnostic).
Goal: Understand which features (e.g., radius, texture, smoothness) contribute most to a tumor being classified as Malignant or Benign.
import warnings
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import shap
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn import metrics
from xgboost import XGBClassifier
warnings.filterwarnings("ignore")
# Configure plots
plt.style.use("seaborn-v0_8-darkgrid")
plt.rc("font", size=14)1. Chargement et préparation des données¶
Le jeu de données Breast Cancer Wisconsin (Diagnostic) est un problème classique de classification binaire.
Classes : Malin (0) vs Bénin (1) dans sklearn par défaut, mais nous les cartographierons clairement.
Caractéristiques : 30 caractéristiques numériques calculées à partir d’une image numérisée d’une aspiration à l’aiguille fine (FNA) d’une masse mammaire.
# Load data
data = load_breast_cancer()
feature_names = data.feature_names
target_names = data.target_names
# Create DataFrame
df = pd.DataFrame(data.data, columns=feature_names)
df["target"] = data.target
# Check distribution
# Note: In sklearn, 0 = Malignant, 1 = Benign.
# For medical context, usually "Positive" case is Malignant. Let's inspect carefully.
print(f"Classes: {target_names}")
print(df["target"].value_counts().rename(index={0: "Malignant", 1: "Benign"}))Classes: ['malignant' 'benign']
target
Benign 357
Malignant 212
Name: count, dtype: int64
# Split data
X = df.drop(columns=["target"])
y = df["target"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)2. Entraînement du modèle avec XGBoost¶
On entraîne un modèle de gradient boosting pour classer les tumeurs.
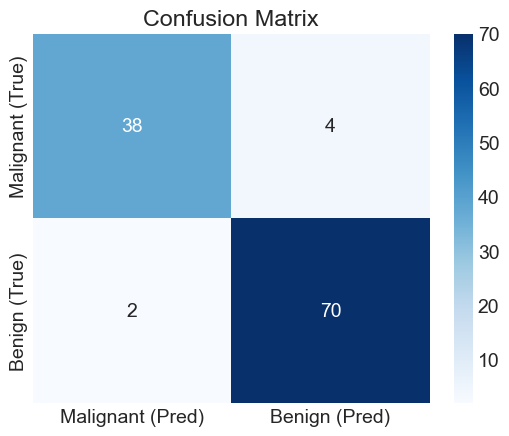
Performance du Modèle : Le modèle XGBoost atteint une excellente précision (~ 95%) sur le jeu de test, ce qui valide la fiabilité des explications qui suivent.
# Initialize XGBoost
# We use logloss for binary classification
model = XGBClassifier(
n_estimators=100,
max_depth=4,
learning_rate=0.1,
use_label_encoder=False,
eval_metric="logloss",
random_state=42,
)
model.fit(X_train, y_train)
# Evaluate
y_pred = model.predict(X_test)
acc = metrics.accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {acc:.4f}")
cm = metrics.confusion_matrix(y_test, y_pred)
sns.heatmap(
cm,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=["Malignant (Pred)", "Benign (Pred)"],
yticklabels=["Malignant (True)", "Benign (True)"],
)
plt.title("Confusion Matrix")
plt.show()Model Accuracy: 0.9474
Application de SHAP¶
Nous utilisons TreeExplainer qui est optimisé pour les modèles basés sur des arbres comme XGBoost.
# Create Explainer
# Explicitly use the booster from the sklearn wrapper to avoid version mismatch issues
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
print("SHAP values shape:", shap_values.shape)SHAP values shape: (569, 30)
Interprétabilité globale : Summary Plot¶
Ce graphique classe les caractéristiques par leur impact sur la sortie du modèle.
Couleur : Valeur de la caractéristique (Rouge = Élevée, Bleu = Faible).
Axe X : Valeur SHAP (Impact sur la sortie du modèle).
Remarque : Puisque la classe 1 est Bénin et 0 est Malin, les valeurs SHAP négatives poussent vers Malin, les valeurs positives vers Bénin.
plt.figure(figsize=(10, 8))
shap.summary_plot(shap_values, X, show=False)
plt.title("SHAP Summary Plot: Impact on Benign Prediction")
plt.tight_layout()
plt.show()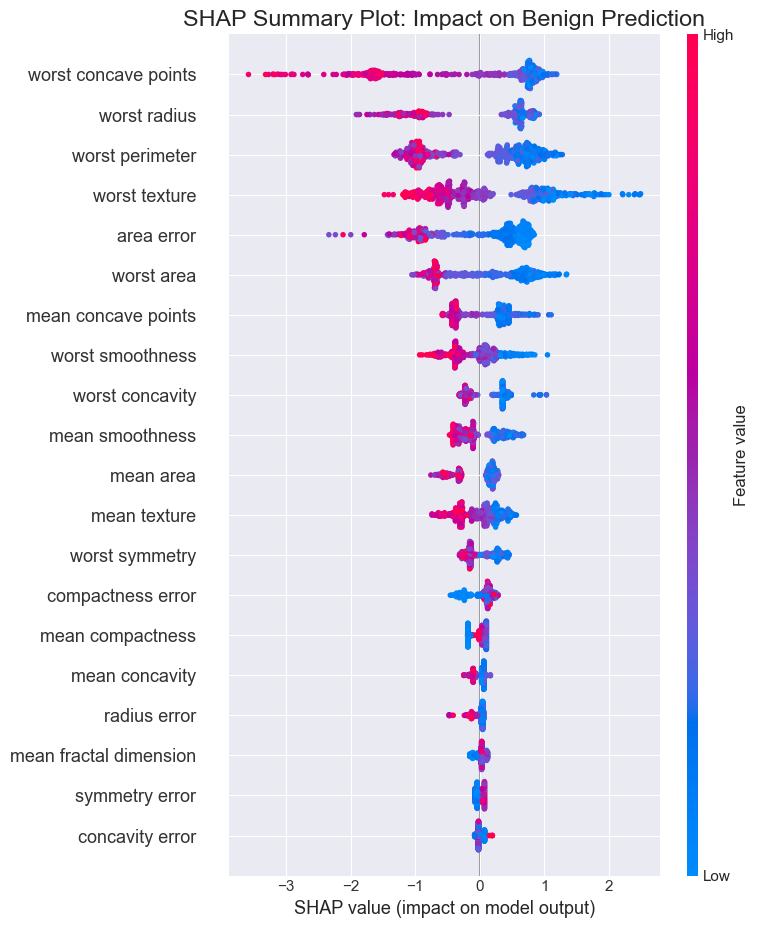
Interprétation Globale (Summary Plot) :
Les variables les plus influentes sont situées en haut du graphique (ex:
worst concave points,worst perimeter).La couleur indique la valeur de la variable (Rouge = Élevée, Bleu = Faible).
On observe que des valeurs élevées (rouge) pour des caractéristiques comme le “rayon” ou le “périmètre” entraînent des valeurs SHAP négatives. Dans ce modèle (0=Malin, 1=Bénin), cela signifie qu’elles poussent la prédiction vers “Malin”, ce qui est cohérent cliniquement (les tumeurs plus grosses et irrégulières sont plus souvent malignes).
Local Interpretability: Force Plot¶
Ici, on observe une instance spécifique (par exemple un cas Malin) pour voir pourquoi le modèle l’a prédite ainsi.
Interprétation Locale (Force Plot) :
Pour l’instance spécifique analysée (un cas Malin), le graphique montre les “forces” qui s’opposent.
Les flèches rouges (poussant vers Bénin) et bleues (poussant vers Malin) permettent de voir exactement pourquoi ce patient a reçu ce diagnostic.
Cela offre une transparence cruciale pour l’aide à la décision médicale.
# Find a Malignant case (Target=0)
malignant_idx = np.where(y == 0)[0][0]
print(f"Analyzing Instance {malignant_idx} (True Class: Malignant)")
print(
f"Model Prediction: {'Benign' if model.predict(X.iloc[[malignant_idx]])[0] == 1 else 'Malignant'}"
)
shap.initjs()
# Force plot for a single observation
# Note: matplotlib=True needed for static output in scripts, but typically this is interactive JS
shap.force_plot(
explainer.expected_value,
shap_values[malignant_idx],
X.iloc[malignant_idx],
matplotlib=True,
show=False,
)
plt.title(f"Force Plot for Instance {malignant_idx}")
plt.show()Analyzing Instance 0 (True Class: Malignant)
Model Prediction: Malignant
