Introduction¶
Data can tell stories in countless ways. Consider a simple yet intriguing example: imagine thousands of points scattered across a two-dimensional plane, collectively forming the word hello.
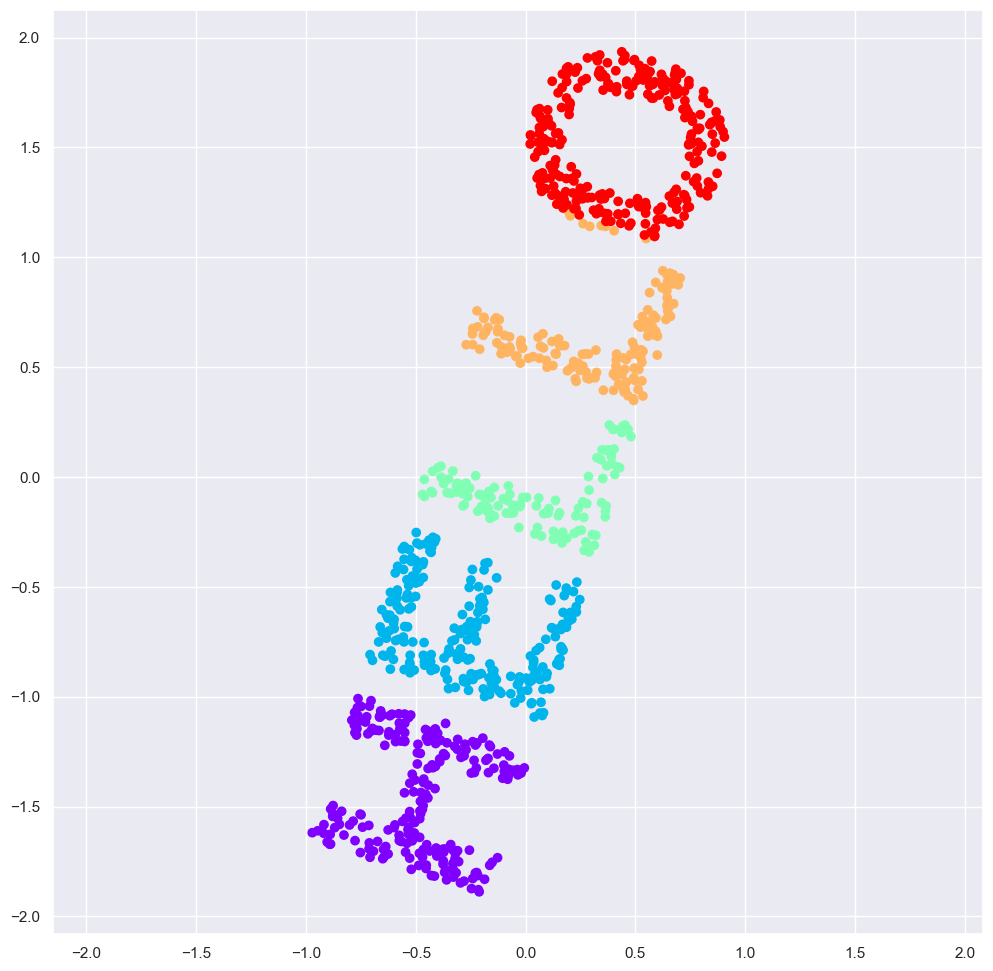
While we could describe this data as a precise collection of coordinates, our minds naturally gravitate toward a more abstract interpretation: “points arranged to spell hello with specific stylistic characteristics.” This shift from raw coordinates to a higher-level description demonstrates how we instinctively seek meaningful patterns in data.
This abstract representation, though less precise, captures something profound about the data’s structure. When we describe it as "the word hello, we’re leveraging our understanding of language, typography, and visual patterns. This interpretation isn’t merely a simplification—it’s a transformation that relies on our hierarchical understanding of concepts like letters, words, and visual style.
Consider how you would memorize multiple such datasets. Rather than remembering individual point coordinates, you might focus on key features: the words themselves, font characteristics, point density, and spacing between letters. This natural tendency to organize information hierarchically allows us to compress complex data into meaningful representations.
This cognitive ability to distill data into its essential components hints at a fundamental principle: beneath complex data often lies a simpler, structured representation based on meaningful patterns and relationships.
Manifold Learning draws inspiration from this idea, though with a more focused objective. Rather than attempting to replicate human-level understanding, it seeks to discover lower-dimensional representations that preserve the essential structure of high-dimensional data.
The core insight is that data points, though seemingly scattered in a high-dimensional space, often lie close to a lower-dimensional, non-linear subspace. This subspace, known as a manifold, captures the intrinsic structure of the data.
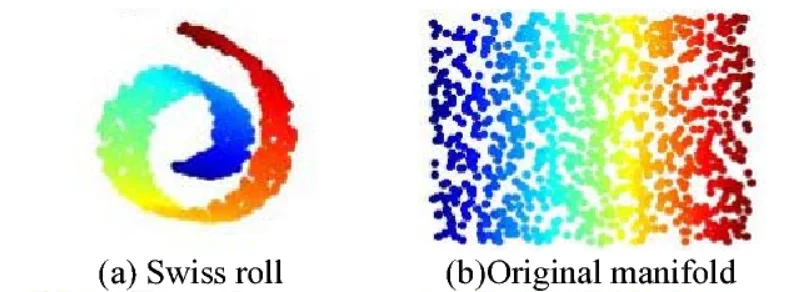
This manifold concept is particularly relevant in today’s data-rich world. Consider a collection of face photographs: while each image might consist of thousands of pixels (high-dimensional data), the meaningful variations between faces can often be described using far fewer parameters—such as the distance between eyes, face shape, or skin tone. These parameters form a lower-dimensional manifold that captures the essential characteristics of faces.
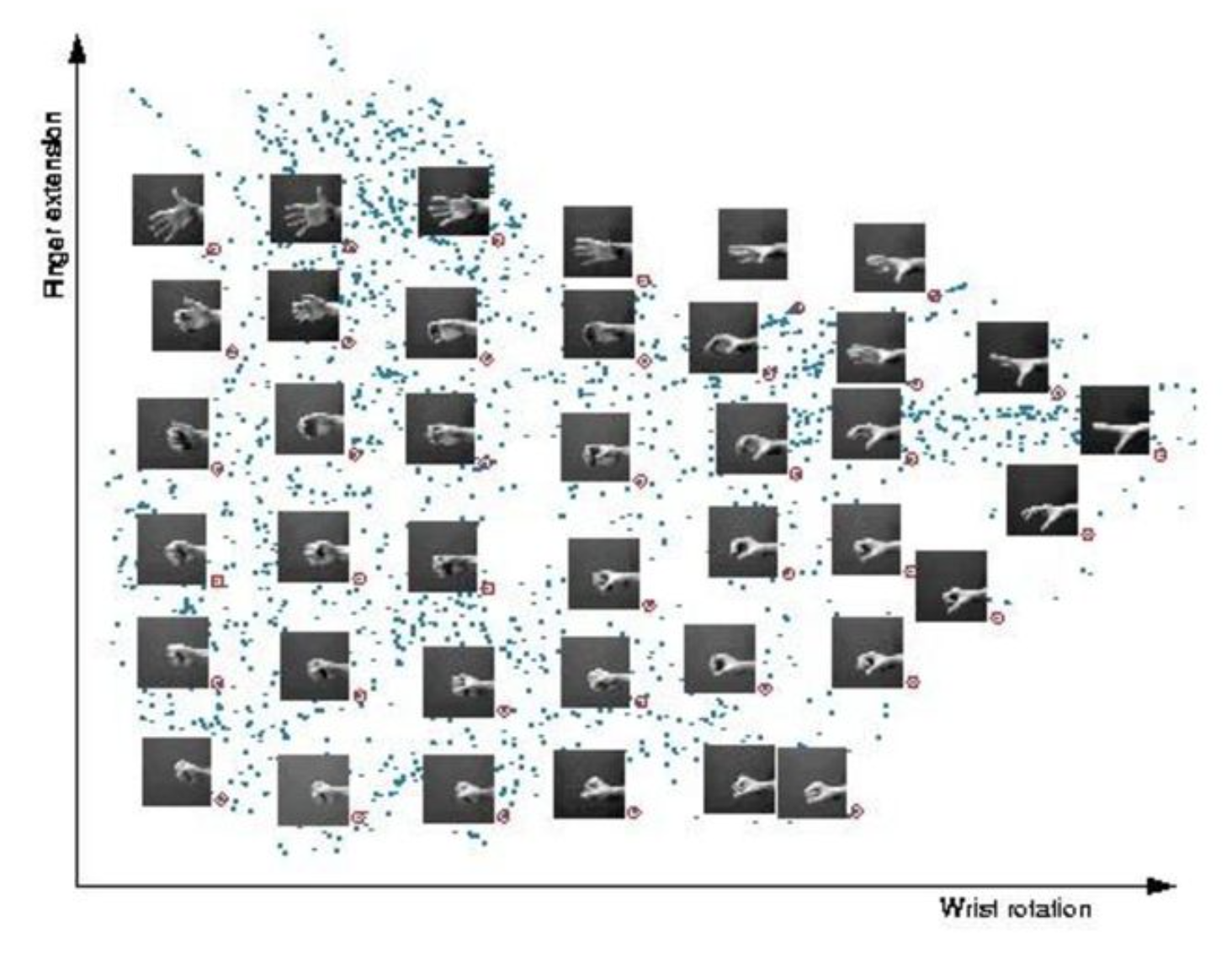
Understanding manifolds isn’t just a theoretical exercise—it’s crucial for practical applications. When we reduce data dimensionality while preserving its fundamental structure, we can:
- Make complex datasets more manageable and computationally tractable
- Reveal hidden patterns and relationships that were obscured in the original high-dimensional space
- Improve the performance of machine learning algorithms by focusing on the most relevant aspects of the data
However, finding these meaningful lower-dimensional representations presents significant challenges. Unlike linear dimensionality reduction techniques such as Principal Component Analysis (PCA), real-world data often lies on curved or twisted manifolds that require more sophisticated approaches to uncover. This is where manifold learning algorithms come into play, offering various strategies to discover and exploit these intrinsic structures.
This document introduce and illustrate the following manifold learning techniques :
- Multi-dimensional Scaling (MDS)
- Isomap
- Locally Linear Embedding (LLE)
- Modified Locally Linear Embedding (MLLE)
- Hessian Eigenmapping (HLLE)
- Local Tangent Space Alignment (LTSA)
- Spectral Embedding
- t-distributed Stochastic Neighbor Embedding (t-SNE)
For each technique, the following aspects will be discussed:
- Principle: What is the main idea behind this method ? How does this method transform the original data representation?
- Theoretical Aspect: What specific optimization problem is formulated to obtain the new data representation? What are the key variables being optimized?
- Solution Methodology: What is the algorithmic approach used to solve the optimization problem? Are there any specific numerical methods or iterative procedures involved?
- Global Optimality: Does the solution method guarantee finding a global minimum? What are the conditions under which global optimality can or cannot be achieved? Are there any potential limitations or local minima issues?
At the end of this document there is an implementation for each presented algorithm.
Data Availability¶
L’ensemble des fichiers et données relatif à ce travail sont disponible en accès libre sur le dépot GitHub sous licence MIT.