Approches non linéaires
Techniques d’échantillonnage et d’ensemble¶
Bootstrap / Bagging¶
Concept¶
Le Bagging (Bootstrap Aggregating) crée plusieurs modèles en échantillonnant avec remplacement l’ensemble de données original, puis agrège leurs prédictions pour améliorer la stabilité et la précision.
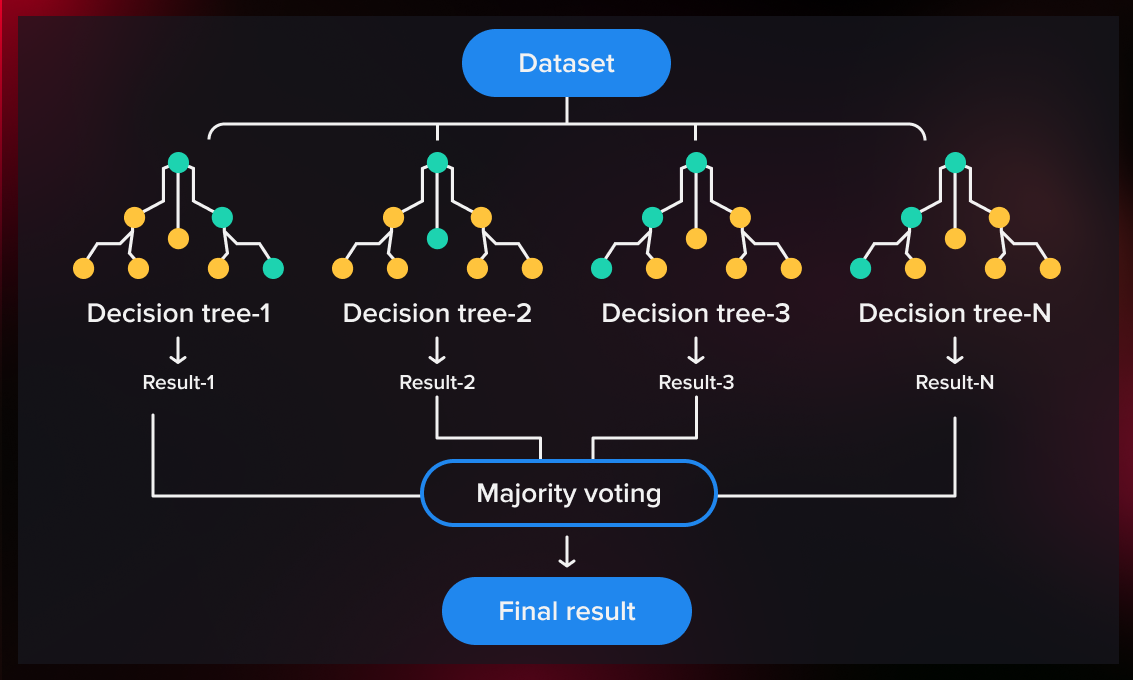
Fonctionnement¶
Si nous avons un ensemble de données , le bagging crée échantillons bootstrap en tirant exemples avec remplacement de . Un modèle est construit sur chaque échantillon . La prédiction finale est:
Pour la régression:
Pour la classification:
Avantages¶
- Réduit la variance sans augmenter le biais
- Parallélisable (chaque modèle peut être entraîné indépendamment)
- Efficace contre le surapprentissage
Inconvénients¶
- Ne réduit pas le biais des modèles sous-jacents
- Perte d’interprétabilité
- Coût computationnel plus élevé que les modèles individuels
Boosting¶
Concept¶
Le Boosting construit séquentiellement des modèles où chaque nouveau modèle tente de corriger les erreurs des modèles précédents, donnant plus de poids aux exemples mal classifiés.
Fonctionnement¶
Pour un problème de classification binaire , avec des classificateurs faibles , le boosting fonctionne ainsi:
Initialisation: pour tout
Pour :
- Entraîner un classificateur faible sur la distribution
- Calculer l’erreur pondérée:
- Calculer le poids du modèle:
- Mettre à jour la distribution: où est un facteur de normalisation
Le classificateur final est:
Avantages¶
- Réduit à la fois le biais et la variance
- Peut créer un modèle fort à partir de classificateurs faibles
- Très performant sur une grande variété de problèmes
Inconvénients¶
- Sensible aux valeurs aberrantes et au bruit
- Risque de surapprentissage si trop d’itérations
- Pas facilement parallélisable (nature séquentielle)
Algorithmes non linéaires¶
Arbres de décisions¶
Concept général¶
Un arbre de décision est un modèle qui prédit la valeur d’une variable cible en apprenant des règles de décision simples déduites des caractéristiques des données.
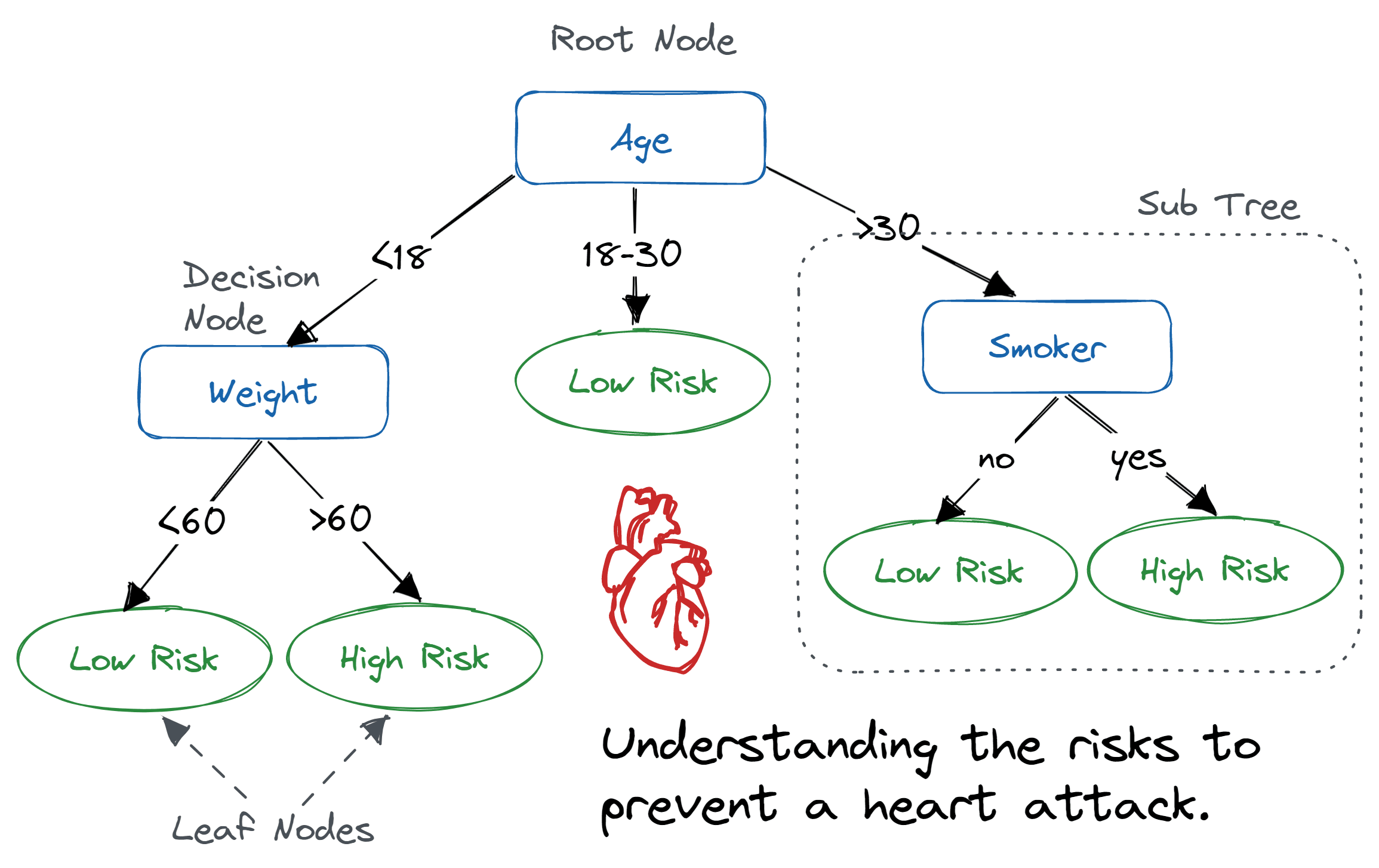
Fonctionnement¶
Pour construire un arbre, on sélectionne à chaque nœud la caractéristique qui maximise le gain d’information (ou minimise l’impureté). Pour la classification, on utilise généralement l’entropie ou l’indice de Gini:
Entropie:
Indice de Gini:
où est la proportion d’éléments de classe dans l’ensemble .
Le gain d’information est calculé par:
où est le sous-ensemble où l’attribut a la valeur .
Avantages¶
- Facile à comprendre et à interpréter
- Nécessite peu de préparation des données
- Peut gérer des variables numériques et catégorielles
Inconvénients¶
- Tendance à créer des arbres trop complexes (surapprentissage)
- Instabilité (petits changements dans les données peuvent entraîner un arbre très différent)
- Performance limitée sur certains problèmes complexes
Forêts Aléatoires¶
Concept¶
Une forêt aléatoire combine le principe du bagging avec une sélection aléatoire de caractéristiques à chaque nœud, créant ainsi un ensemble d’arbres de décision diversifiés.
Fonctionnement¶
Une forêt aléatoire construit arbres de décision sur des échantillons bootstrap. À chaque nœud, au lieu de considérer toutes les caractéristiques, on n’en considère qu’un sous-ensemble choisi aléatoirement.
La prédiction finale est:
Pour la régression:
Pour la classification:
Pour évaluer l’importance des variables, on peut utiliser la diminution moyenne de l’impureté (MDI):
où est la variable utilisée pour la division au nœud , est la proportion d’échantillons atteignant , et est la diminution d’impureté.
Avantages¶
- Performance supérieure à celle des arbres individuels
- Robustesse au surapprentissage
- Gère efficacement les grandes dimensions et les données manquantes
Inconvénients¶
- Moins interprétable qu’un arbre de décision unique
- Coût computationnel et de mémoire élevé
- Difficulté à modéliser certaines relations linéaires simples
AdaBoost¶
Concept¶
AdaBoost (Adaptive Boosting) est un algorithme de boosting qui ajuste les poids des exemples mal classifiés à chaque itération et combine des classificateurs faibles en un classificateur fort.
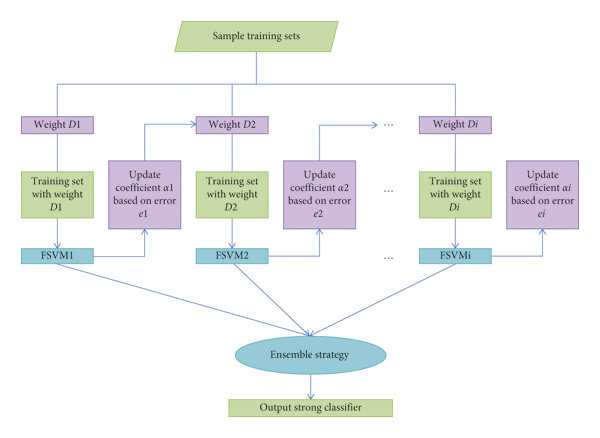
Fonctionnement¶
AdaBoost fonctionne comme suit:
Initialisation: pour
Pour :
- Entraîner un classificateur faible en utilisant les poids
- Calculer l’erreur pondérée:
- Calculer le coefficient:
- Mettre à jour les poids:
- Normaliser:
Le classificateur final est:
Avantages¶
- Simple à implémenter
- Bonne performance sur de nombreux jeux de données
- S’adapte automatiquement à l’importance relative des caractéristiques
Inconvénients¶
- Sensible aux valeurs aberrantes et au bruit
- Peut être surpassé par d’autres algorithmes de boosting (comme XGBoost)
- Peut conduire au surapprentissage sur des données bruitées