Méthodologie générale
Préparation des données¶
Le jeu de données est divisé en deux parties : un ensemble d’entraînement et un ensemble de test. L’ensemble d’entraînement est utilisé pour entraîner les modèles et ajuster les hyperparamètres, tandis que l’ensemble de test est utilisé pour évaluer les performances des modèles sur des données non vues.
Optimisation des hyperparamètres¶
Les données d’entrainement sont utilisées pour ajuster les hyperparamètres des modèles. Les hyperparamètres sont des paramètres qui ne sont pas appris par le modèle lui-même, mais qui doivent être définis par l’utilisateur avant l’entraînement. Ils permettent de contrôler le comportement du modèle et d’optimiser ses performances.
On utilise la validation croisée pour évaluer les performances du modèle pour différentes valeurs des hyperparamètres, puis on sélectionne les valeurs qui maximisent les performances du modèle. Cette approche permet de trouver les hyperparamètres optimaux pour chaque modèle et d’obtenir des performances optimales.
Grid Search¶
Une méthode courante pour l’optimisation des hyperparamètres est la recherche sur grille (Grid Search). Cette technique consiste à définir un ensemble de valeurs possibles pour chaque hyperparamètre et à entraîner le modèle avec toutes les combinaisons possibles de ces valeurs. Chaque configuration est évaluée à l’aide de la validation croisée, et la meilleure combinaison d’hyperparamètres est sélectionnée en fonction des performances obtenues.
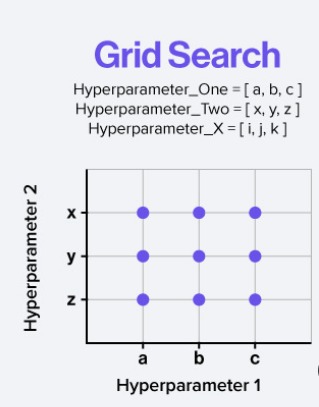
L’avantage de la recherche sur grille est qu’elle garantit d’explorer systématiquement toutes les combinaisons définies, ce qui peut conduire à une configuration optimale du modèle. Cependant, cette méthode peut être coûteuse en temps de calcul, surtout lorsque le nombre d’hyperparamètres à optimiser est élevé. Pour pallier cet inconvénient, des techniques plus efficaces comme la recherche aléatoire (Random Search) ou l’optimisation bayésienne peuvent être utilisées.
Halving Random Search¶
Halving Random Search est une méthode d’optimisation des hyperparamètres qui combine les avantages de la recherche aléatoire et de la recherche sur grille. Elle consiste à échantillonner aléatoirement un sous-ensemble des combinaisons d’hyperparamètres possibles et à évaluer leur performance à l’aide de la validation croisée. Les configurations les plus performantes sont ensuite sélectionnées pour être évaluées à nouveau avec un nombre plus élevé de plis de validation croisée. Ce processus est répété jusqu’à ce qu’une configuration optimale soit trouvée.
K-Fold Cross Validation¶
La validation croisée (en anglais cross-validation) est une méthode d’évaluation qui consiste à diviser l’ensemble des données d’entraînement en plusieurs sous-ensembles appelés “plis” (folds). À chaque itération, un pli est utilisé pour tester le modèle, tandis que les autres plis servent à l’entraîner. Ce processus se répète pour chaque pli, de sorte que chaque sous-ensemble est utilisé à la fois pour l’entraînement et pour le test.
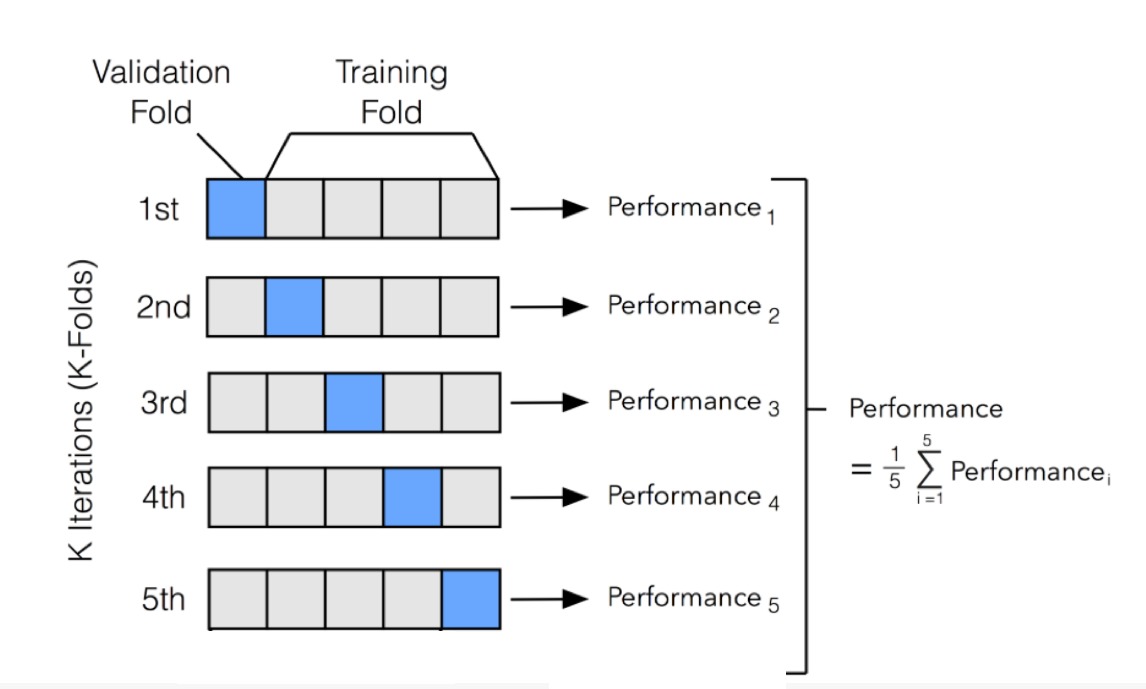
Cette méthode permet d’obtenir une évaluation plus robuste des performances du modèle en réduisant le risque de surajustement et en prenant en compte la variabilité des données. Elle est particulièrement utile lorsque l’ensemble de données est de petite taille ou que les classes sont déséquilibrées.
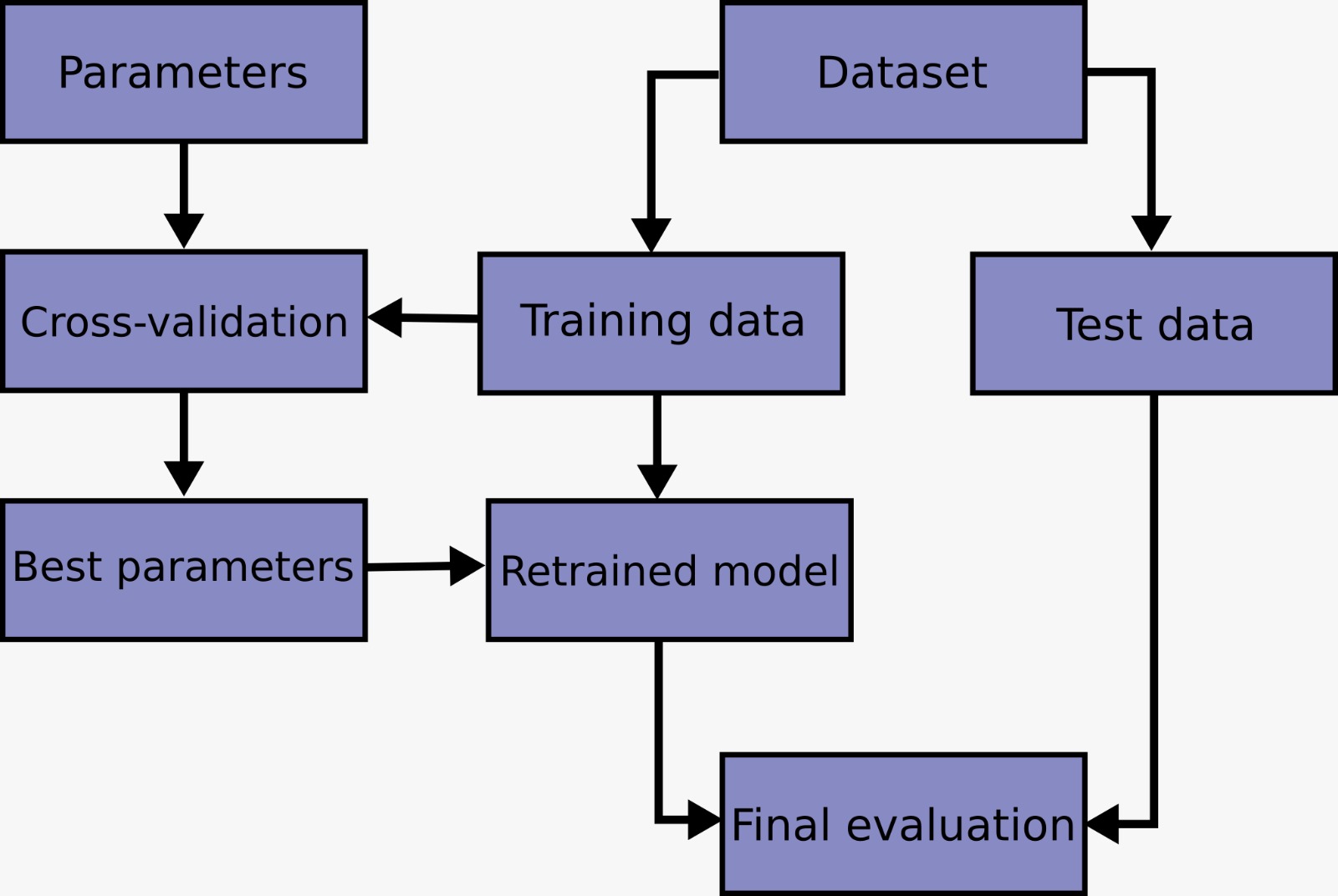
Résumé de la méthodologie¶
Le schéma ci-dessous illustre le processus complet d’entraînement des modèles, de la préparation des données à l’évaluation des performances.
Feature engineering¶
Le Feature Engineering, ou plus généralement Pre-Processing est un processus essentiel dans le développement de modèles d’apprentissage automatique. Il consiste à transformer les données brutes en caractéristiques exploitables par les modèles :
- Nettoyer les données inutiles, redondantes ou même nuisible pour l’entraînement du modèle.
- Gérer les valeurs manquantes en les imputant ou en supprimant les observations concernées.
- Détecter et traiter les valeurs aberrantes pour éviter qu’elles influencent négativement le modèle.
- Réduire la dimensionnalité des données pour améliorer les performances des modèles et limiter le surapprentissage.
- Normaliser les données pour les rendre comparables et cohérentes et faciliter la convergence des algorithmes.
- Encodage des variables catégoriques pour les rendre exploitables par les modèles
- Équilibrer les classes pour éviter les biais de prédiction
Dans ce projet de classification binaire, le pré-traitement suivant est appliqué:
- Normalisation des variables numériques : les valeurs numériques sont mises à l’échelle pour les rendre comparables et faciliter la convergence des algorithmes.
Classes déséquilibrées¶
L’un des enjeux liés aux problèmes de classification est la présence de classes déséquilibrées. On parle de classes déséquilibrées lorsque les données d’entraînement contiennent un grand déséquilibre entre le nombre d’exemples de chaque classe.
Ce déséquilibre peut poser plusieurs défis pour l’apprentissage automatique :
- Apprentissage insuffisant : avec moins de données d’apprentissage pour la classe minoritaire, le modèle ne parvient pas à reconnaître efficacement les caractéristiques distinctives de la classe minoritaire.
- Le modèle favorise la bonne classification de la classe majoritaire, car il minimise l’erreur globale en classant la plupart des exemples dans la classe majoritaire.
- Les métriques de performance du modèle sur-représente la performance du modèle à évaluer la classe majoritaire.
Toutefois, certain algorithmes de machine learning sont plus robustes face à des classes déséquilibrées, comme les SVM et les arbres de décision.
Plusieurs solutions peuvent être mises en place pour pallier ces problèmes, comme le sur-échantillonnage de la classe minoritaire, le sous-échantillonnage de la classe majoritaire, ou la création de données synthétiques à l’aide d’interpolation afin de rééquilibrer les classes. Certains modèles permettent aussi de donner plus de poids aux exemples de la classe minoritaire pour les rendre plus importants lors de l’apprentissage.
Pour l’algorithme SVM, une variante avec un preproceseur appelé SMOTE est introduit. Celui-ci permet d’échantilloner la classe minoritaire afin de renforcer la représentativité de la classe sous-représentée et d’améliorer les performances du modèle.
Il est aussi possible d’ajuster les hyperparamètres des modèles pour qu’ils soient plus sensibles aux classes minoritaires, ou de définir des métriques de performance plus adaptées aux classes déséquilibrées, comme le F1-score ou l’aire sous la courbe ROC.
Pré-traitement et fuite de données¶
Ces étapes d’entraînement seront appliquées aux données d’entraînement lors de la phase d’entraînement du modèle et aux données de test lors de la phase d’évaluation du modèle.
Métrique d’évaluation des modèles¶
Une fois le modèle entraîné, il est important d’évaluer ses performances pour vérifier s’il fait de bonnes prédictions. Dans le cadre d’une classification binaire, on peut définir les termes suivants :
- Matrice de confusion
- La matrice de confusion est une matrice 2x2 qui résume les prédictions du modèle par rapport aux valeurs réelles et permet de visualiser les performances d’un algorithme de classification. Elle contient quatre éléments :
- les vrais positifs (TP) : nombre de fois où le modèle prédit correctement la classe positive.
- les faux positifs (FP) : nombre de fois où le modèle prédit la classe positive alors qu’elle est négative.
- les vrais négatifs (TN) : nombre de fois où le modèle prédit la classe négative alors qu’elle est positive.
- les faux négatifs (FN) : nombre de fois où le modèle prédit correctement la classe négative.
À partir de cette matrice, plusieurs mesures sont calculées :
- Exactitude
- L’exactitude (ou en anglais accuracy) mesure la proportion de prédictions correctes parmi toutes les prédictions effectuées par le modèle. Elle est définie par :
- Précision
- La précision (ou en anglais precision) mesure la proportion de vrais positifs parmi tous les éléments identifiés comme positifs par le modèle. Elle permet d’évaluer la capacité du modèle à éviter les faux positifs et est définie par :
- Rappel
- Le rappel (ou en anglais recall) mesure la proportion de vrais positifs correctement identifiés parmi tous les éléments réellement positifs. Il permet d’évaluer la capacité du modèle à détecter tous les cas positifs et est défini par :
- F1-score
- Le F1-score est la moyenne harmonique de la précision et du rappel (). Il permet d’évaluer la performance globale d’un modèle en équilibrant ces deux métriques. Un score proche de 1 indique une excellente performance.
- Weighted Average F1-score
- Le F1-score moyen pondéré est une mesure utilisée pour évaluer les performances d’un modèle de classification binaire. Il prend en compte le déséquilibre des classes en calculant une moyenne pondérée des F1-scores de chaque classe, où les poids sont proportionnels au nombre d’instances de chaque classe. Cela permet d’obtenir une évaluation plus représentative des performances globales du modèle, en particulier lorsque les classes sont déséquilibrées.
La grande partie des modèles de classifications binaires produisent en sortie un chiffre entre 0 et 1, qui peut être vu comme la probabilité que l’observation appartienne à la classe positive.
Pour transformer ces chiffres en classes, on utilise un seuil de décision. Si la probabilité est supérieure à ce seuil, l’observation est classifiée en tant que classe positive, sinon elle est classifiée en tant que classe négative.
L’analyse des probabilités prédites par un modèle permet de déterminer le seuil de décision optimal pour maximiser les performances du modèle. La plupart des modèles de classification binaire utilisent un seuil de décision par défaut de 0.5, mais ce seuil peut être ajusté pour améliorer les performances du modèle en fonction des besoins spécifiques de l’application.
Par exemple, dans le cas de la détection de maladies, il est préférable de privilégier un taux de faux positifs élevé pour éviter de passer à côté de cas positifs. Dans ce cas, le seuil de décision peut être abaissé pour augmenter le rappel du modèle, même au détriment de la spécificité.
L’analyse des probabilités prédites par un modèle permet aussi de remarquer la capacité du modèle à distinguer plus ou moins bien les classes positives et négatives. Une probabilité de 0.9 pour une observation positive signifie que le modèle est très sûr de sa prédiction, tandis qu’une probabilité de 0.6 indique une prédiction moins certaine.
Certains graphiques permettent de visualiser les performances des modèles selon ce seuil :
- Courbe de précision-rappel
- La courbe de précision-rappel affiche la précision et le rappel en fonction du seuil de décision. Elle permet d’évaluer la performance du modèle en fonction de ces deux métriques. Plus la courbe est proche du coin supérieur droit, meilleure est la performance du modèle.
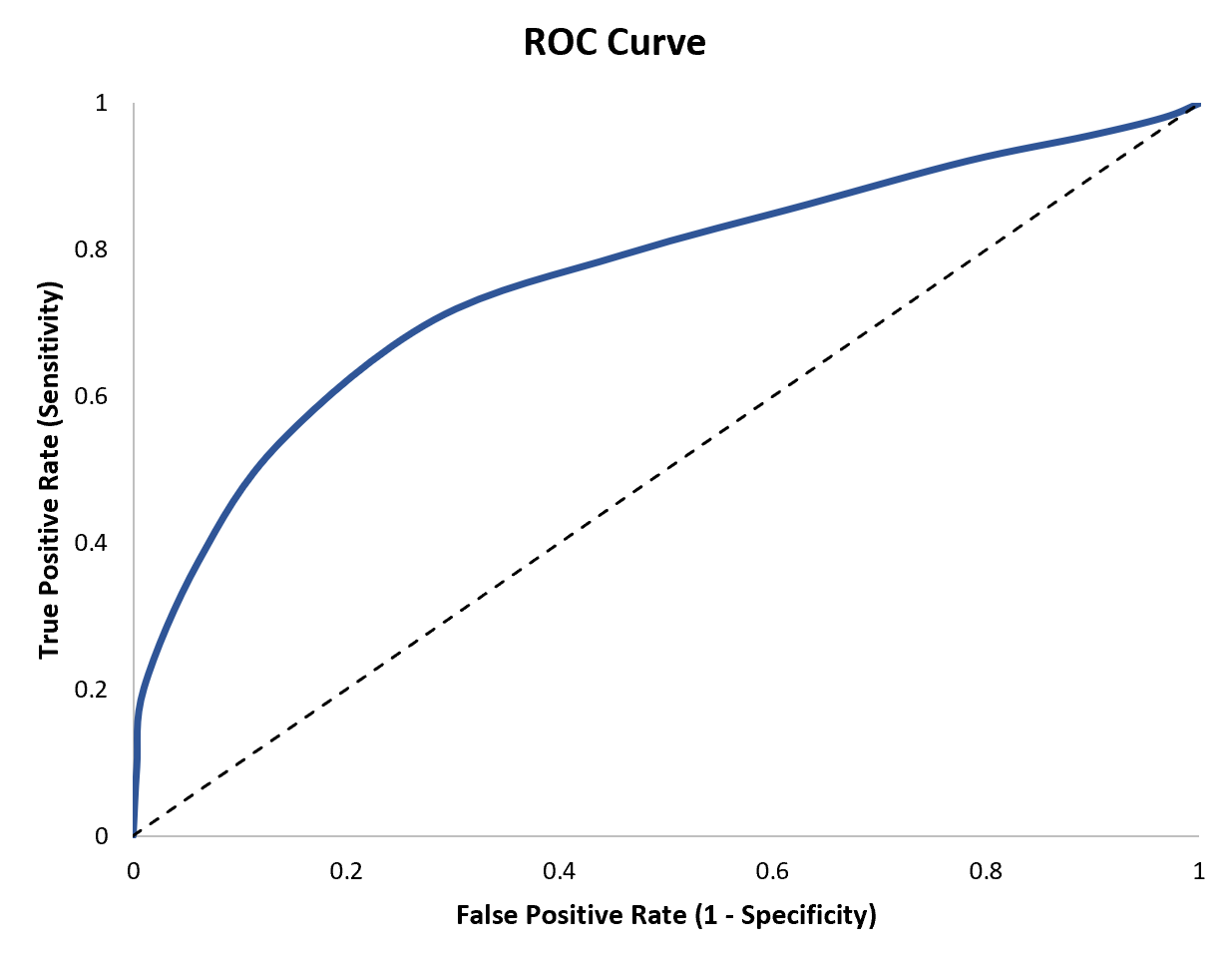
- Courbe ROC (Receiver Operating Characteristic)
- La courbe ROC permet d’évaluer la performance d’un classificateur binaire, c’est-à-dire un système conçu pour diviser des éléments en deux catégories distinctes en fonction de certaines caractéristiques. Cette mesure est illustrée par une courbe qui affiche le taux de vrais positifs en fonction du taux de faux positifs. Elle permet d’observer la capacité du modèle à correctement distinguer les classes positives et négatives et de visualier l’arbitrage réalisé entre les taux de faux positifs et de vrais négatifs. De plus l’aire sous la courbe (AUC) permet de quantifier la performance du modèle : plus la valeur est proche de 1, plus le modèle est performant pour déterminer les classes positives et négatives.