Approches non paramétriques
K-Nearest Neighbors (KNN)¶
Concept¶
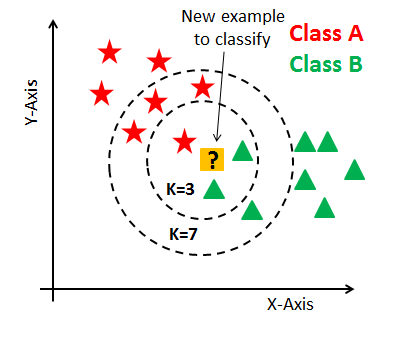
L’algorithme KNN est une méthode de classification et de régression non paramétrique qui classe un nouvel exemple en fonction des classes des k exemples qui lui sont les plus proches dans l’espace des caractéristiques.
Aspect théorique¶
Pour un point de données x à classifier :
- On calcule la distance (généralement euclidienne) entre x et tous les points de l’ensemble d’apprentissage
- On sélectionne les k points les plus proches de x
- Pour la classification : on attribue à x la classe majoritaire parmi ces k voisins
- Pour la régression : on calcule la moyenne des valeurs cibles des k voisins
où représente l’ensemble des k plus proches voisins de x.
Avantages¶
- Simple à comprendre et à implémenter
- Aucune hypothèse sur la distribution des données
- Efficace pour les petits ensembles de données
- S’adapte naturellement aux problèmes multi-classes
Inconvénients¶
- Coûteux en calcul pour de grands ensembles de données
- Sensible au choix de k et à la métrique de distance
- Performances réduites avec des données de haute dimension (malédiction de la dimensionnalité)
- Sensible aux données bruitées et aux valeurs aberrantes
Distance-Weighted KNN¶
Concept¶
Une amélioration du KNN classique où les voisins les plus proches ont plus d’influence sur la prédiction grâce à une pondération inversement proportionnelle à leur distance.
Aspect théorique¶
Contrairement au KNN standard où tous les voisins ont le même poids, le Distance-Weighted KNN attribue un poids à chaque voisin en fonction de sa distance au point à prédire.
Pour un point x à classifier :
- On calcule la distance entre x et tous les points de l’ensemble d’apprentissage
- On sélectionne les k points les plus proches
- On attribue un poids à chaque voisin, généralement où d est la distance
- Classification : on vote avec pondération par classe
- Régression : on calcule la moyenne pondérée des valeurs cibles
Avantages¶
- Moins sensible au choix de k que le KNN standard
- Meilleure prise en compte de la structure locale des données
- Plus robuste face aux valeurs aberrantes (si elles sont éloignées)
Inconvénients¶
- Calcul légèrement plus complexe que le KNN standard
- Toujours sensible à la malédiction de la dimensionnalité
- Le choix de la fonction de pondération peut influencer les résultats
Condensed Nearest Neighbor (CNN)¶
Concept¶
Le CNN est une technique de réduction de l’ensemble d’apprentissage qui conserve uniquement les exemples essentiels à la frontière de décision, réduisant ainsi le coût de calcul du KNN.
Aspect théorique¶
L’algorithme crée un sous-ensemble minimal S de l’ensemble d’apprentissage original T tel que la classification 1-NN utilisant S donne les mêmes résultats que celle utilisant T.
L’algorithme fonctionne comme suit :
- Initialiser S avec un exemple aléatoire de chaque classe
- Pour chaque point x dans T qui n’est pas dans S :
- Classifier x en utilisant S et la règle 1-NN
- Si x est mal classé, l’ajouter à S
- Répéter l’étape 2 jusqu’à ce qu’aucun point ne soit ajouté à S
Ce processus conserve principalement les points proches des frontières de décision, réduisant considérablement la taille de l’ensemble de référence.
Avantages¶
- Réduit significativement la taille de l’ensemble de données (et donc le temps de calcul)
- Préserve la précision de classification dans les cas simples
- Permet d’identifier les exemples les plus importants pour la décision
Inconvénients¶
- Sensible à l’ordre de présentation des exemples
- Peut être instable avec des données bruitées
- Peut ne pas fonctionner optimalement avec des frontières de décision complexes
- Ne prend pas en compte le paramètre k (utilise k=1)
Locally Adaptive Nearest Neighbors¶
Concept¶
Cette variante adapte localement la métrique de distance en fonction de la densité et de la distribution des données dans différentes régions de l’espace des caractéristiques.
Aspect théorique¶
Plutôt que d’utiliser une mesure de distance fixe comme la distance euclidienne, l’algorithme ajuste la métrique en fonction des caractéristiques locales des données.
Deux approches principales sont utilisées :
Adaptation par métrique de Mahalanobis locale : utilise une matrice de covariance locale pour définir la distance, permettant de prendre en compte les corrélations locales entre les caractéristiques.
où M(x) est la matrice de Mahalanobis locale.
Adaptation par facteur d’échelle : ajuste le facteur d’échelle de la distance en fonction de la densité locale des données.
Ces adaptations permettent à l’algorithme de s’ajuster automatiquement aux variations de densité et d’échelle dans différentes régions de l’espace des caractéristiques.
Avantages¶
- S’adapte mieux aux données avec des distributions variables
- Plus robuste face à la malédiction de la dimensionnalité
- Peut capturer des structures complexes dans les données
- Améliore les performances sur des ensembles de données hétérogènes
Inconvénients¶
- Significativement plus complexe à implémenter
- Coût de calcul élevé pour estimer les métriques locales
- Risque de surajustement si les adaptations locales sont trop spécifiques
- Nécessite plus de données pour estimer correctement les métriques locales
Conclusion¶
Ces quatre algorithmes représentent une évolution progressive de la méthode KNN de base, chacun abordant des limitations spécifiques :
Le Distance-Weighted KNN améliore le KNN standard en introduisant des poids basés sur la distance, offrant plus de nuance dans la prise de décision.
Le Condensed NN adopte une approche différente en se concentrant sur la réduction de la complexité computationnelle du KNN plutôt que sur l’amélioration de sa précision.
Le Locally Adaptive NN est le plus sophistiqué, s’attaquant aux problèmes fondamentaux liés à la mesure de distance elle-même, permettant une plus grande flexibilité et une meilleure adaptation aux données complexes.