Approches paramétriques
Régression logistique¶
Concept¶
La régression logistique est un algorithme de classification qui modélise la probabilité qu’une instance appartienne à une classe particulière. Contrairement à son nom, elle est utilisée pour la classification et non pour la régression. Elle étend le concept de régression linéaire en appliquant une fonction sigmoïde pour transformer la sortie en probabilité entre 0 et 1.
Aspect théorique¶
La régression logistique modélise la probabilité d’appartenance à une classe en utilisant la fonction logistique (sigmoïde) :
où est le vecteur de poids, le vecteur de caractéristiques, et le biais.
L’apprentissage se fait généralement par la méthode de maximum de vraisemblance, en minimisant la fonction de coût de log-vraisemblance négative :
On y ajoute souvent un terme de régularisation (L1, L2 ou mixte (elastic net)) pour éviter le surapprentissage.
Avantages¶
- Simple à implémenter et à interpréter
- Efficace pour les ensembles de données linéairement séparables
- Fournit des probabilités pour les prédictions
Inconvénients¶
- Capacité limitée à capturer des relations non linéaires complexes
- Moins bonnes performances sur des données à haute dimension
- Sensible aux valeurs aberrantes
Support Vector Machine (SVM)¶
Concept¶
L’algorithme SVM cherche à trouver l’hyperplan qui sépare au mieux les classes avec la marge maximale entre les points de données les plus proches de chaque classe (appelés vecteurs de support). Les SVM peuvent gérer des séparations non linéaires grâce à l’astuce du noyau (kernel trick).
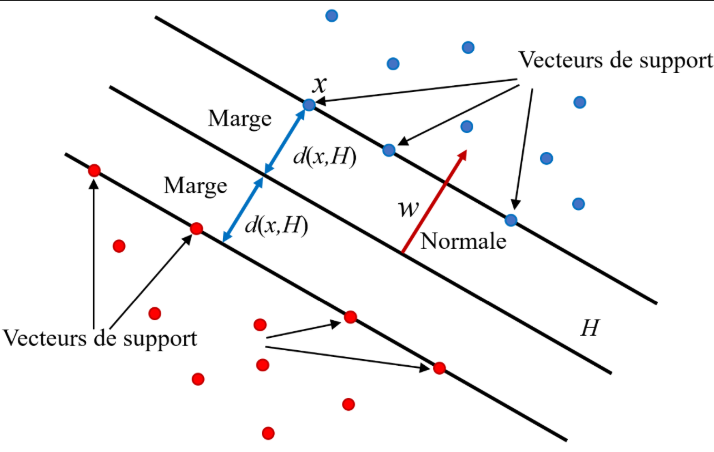
Aspect théorique¶
Pour des données linéairement séparables, le SVM trouve l’hyperplan défini par qui maximise la marge entre les classes. Cela se traduit par le problème d’optimisation :
Pour les données non linéairement séparables, le SVM utilise différents types de noyaux :
Noyau linéaire :
- Utilisé pour des données linéairement séparables
- Rapide et simple
Noyau polynomial :
- Bon pour les problèmes où les caractéristiques interagissent
- Paramètres à régler : degré et constante
Noyau RBF (Gaussien) :
- Très polyvalent, adapté à de nombreux problèmes non linéaires
- Paramètre γ contrôle la flexibilité
Noyau sigmoïde :
- Inspiré des réseaux de neurones
- Moins utilisé que les autres noyaux
Pour gérer le déséquilibre des classes, SVM utilise des pénalités différentes (paramètre C) pour chaque classe :
- Un C plus élevé pour la classe minoritaire donne plus d’importance à sa classification correcte
- Mathématiquement, on modifie la formulation pour avoir et différents selon la classe
Avantages¶
- Efficace dans les espaces de haute dimension
- Robuste contre le surapprentissage grâce à la maximisation de la marge
- Polyvalent grâce aux différents noyaux
- Solution unique (optimisation convexe)
Inconvénients¶
- Choix du noyau et paramétrage complexes
- Calcul coûteux pour de grands ensembles de données
- Difficulté à interpréter le modèle